How to Beat Proprietary LLMs With Smaller Open Source Models

Introduction
When designing systems that use text generation models, many people first turn to proprietary services such as OpenAI's GPT-4 or Google's Gemini. After all, these are the biggest and best models out there, so why use anything else? Eventually, the applications hit a scale that these APIs don't support, or they become cost prohibitive, or the response times are too slow. Open source models can be the solution to all of these problems, but you'll fail to get adequate performance if you attempt to use them the same way you would use a proprietary LLM.
In this article, we explore the unique advantages of open source LLMs, and how you can leverage them to develop AI applications that are not just cheaper and faster than proprietary LLMs, but better too.
Proprietary LLMs versus Open Source LLMs
Table 1 compares the key characteristics of proprietary and open source LLMs. Open source LLMs are assumed to run on user-managed infrastructure, whether that's local or in the cloud. In summary: proprietary LLMs are managed services that offer the most capable, closed source models with the largest context windows, but open source LLMs are preferable in every other way that matters.
| Proprietary LLMs | Open Source LLMs | |
|---|---|---|
| Examples | GPT-4 (OpenAI) Gemini (Google) Claude (Anthropic) |
Gemma 2B (Google) Mistral 7B (Mistral AI) Llama 3 70B (Meta) |
| Software Accessibility | Closed source | Open source |
| Number of parameters | Trillions | Typical sizes: 2B, 7B, 70B |
| Context window | Longer. 100k-1M+ tokens | Shorter. Typically 8k-32k tokens. |
| Capabilities | State of the art performance across all leaderboards and benchmarks | Historically, lag behind proprietary LLMs |
| Infrastructure | Platform as a Service (PaaS), managed by provider. Not configurable. API rate limits apply. | Usually self-managed on cloud infrastructure (IaaS). Fully configurable. |
| Inference Cost | More expensive | Less expensive |
| Speed | Slower, at equivalent price points. Can't be tweaked. | Depends on infrastructure, techniques, and optimisations, but faster. Highly configurable. |
| Throughput | Often capped by API rate limits. | Unrestricted: scales with your infrastructure. |
| Latency | Higher. Can accumulate significant network latency for multi-turn conversations. | No network latency if models are run locally. |
| Functionality | Generally expose a limited set of features through their APIs | Many powerful techniques unlocked by direct access to the model |
| Caching | Not accessible server side | Configurable server-side strategies that improve throughput and reduce cost |
| Fine-tuning | Limited fine-tuning services (e.g. OpenAI) | Full control over fine-tuning |
| Prompt/Flow Engineering | Often cost-prohibitive, or unviable due to rate limits or latency | Unrestricted, and minimal downsides to elaborate control flows |
Table 1. Comparison of proprietary and open source LLM characteristics
The thrust of this article is that by leveraging the advantages of open source models, it is possible to build AI applications with superior task performance than proprietary LLMs, whilst also achieving better throughput and cost profiles.
We'll focus on strategies for open source models that are either impossible or less effective with proprietary LLMs. This means we won't discuss techniques that benefit both, such as few-shot prompting or retrieval augmented generation (RAG).
Requirements of an Effective LLM System
There are some important principles to bear in mind when thinking about how to design effective systems around LLMs.
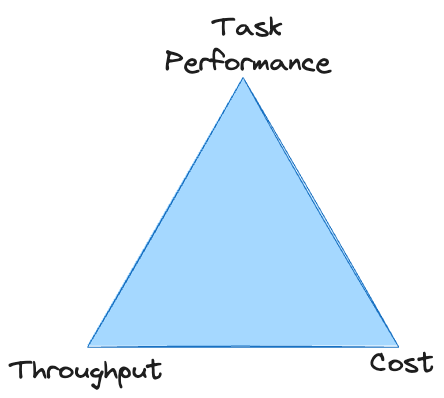
There are direct tradeoffs between task performance, throughput, and cost: it's easy to improve any one of these, but it usually comes at the expense of the other two. Unless you have unlimited budget, it is necessary to meet a minimum standard across all three for a system to be viable. With proprietary LLMs, it's common to get stuck at the top point of the triangle, unable to reach sufficient throughput at an acceptable cost.
We'll briefly touch on the characteristics of each of these non-functional requirements before exploring strategies that can help with each of them.
Throughput
Many LLM systems struggle to achieve sufficient throughput simply because of how slow LLMs are.
Factors other than text generation are relatively insignificant, unless you have especially heavy data processing. LLMs can "read" text much faster than they can generate it — this is because input tokens are computed in parallel, whereas output tokens are generated sequentially.
We need to maximise the speed of text generation without sacrificing quality or incurring excessive costs.

This gives us two levers to pull when aiming to increase throughput:
- Reduce the number of tokens that need to be generated
- Increase the speed of generating each individual token
Many of the strategies that follow aim to improve on one or both of these aspects.
Cost
With proprietary LLMs, you are billed per input and output token. The price per token will correlate with the quality (i.e. size) of the model you're using. This gives you limited options for reducing cost: you either need to reduce the number of input/output tokens, or use a cheaper model (there won't be many too choose from).
With self-hosted LLMs, your costs are determined by your infrastructure. If you're using a cloud service for hosting, you will be billed per unit of time that you "rent" a virtual machine.

Bigger models will require bigger, more expensive, virtual machines. Improving throughput without changing hardware reduces costs, as fewer compute hours are needed to process a fixed amount of data. Equally, throughput can be improved by scaling hardware vertically or horizontally, but this will increase costs.
Strategies for minimising cost focus on enabling smaller models to be used for the task, as these have the highest throughputs and cheapest running costs.
Task Performance
Task performance is the fuzziest of the three requirements, but also the requirement with the broadest scope for optimisation and improvement. One of the main challenges of achieving adequate task performance is measuring it: reliable, quantitative evaluation of LLM outputs is hard to get right.
As we're focussing on techniques that uniquely advantage open source LLMs, our strategies emphasise doing more with less, and exploiting methods that are only possible when you have direct access to the model.
Open Source LLM Strategies that Beat Proprietary LLMs
All of the strategies that follow are effective in isolation, but they're also complementary. They can be applied to different extents to strike the right balance across the system's non-functional requirements, and maximise overall performance.
Multi-turn Conversations and Control Flow
🔴 Reduces throughput
🔴 Increases cost per input
While it's possible to use extensive multi-turn conversation strategies with proprietary LLMs, these are often unviable, as they:
- can be cost prohibitive when billed per token
- may exhaust API rate limits, as they require multiple API calls per input
- may be too slow if the back-and-forth exchanges involve generating many tokens or accumulate significant network latency
This situation is likely to improve over time as proprietary LLMs continue to become faster, more scalable, and more affordable. But for now, proprietary LLMs are often limited to single, monolithic prompting strategies for practical use cases at scale. This is in keeping with the much larger context windows offered by proprietary LLMs: the go-to strategy is often just to cram a ton of information and instructions into a single prompt (which incidentally, has negative cost and speed implications).
With self-hosted models, these downsides of multi-turn conversations are less concerning: per token costs are less relevant; there are no API rate limits; and network latency can be minimised. The smaller context windows and weaker reasoning capabilities of open source models should also dissuade you from monolithic prompts. This leads us to the central strategy for beating proprietary LLMs:
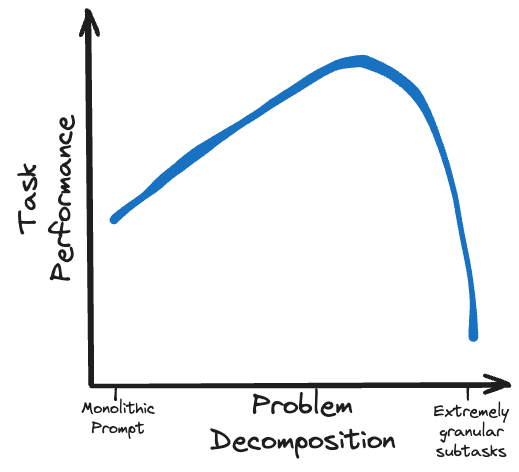
Elaborate multi-turn prompting strategies are viable for local models. Techniques such as chain of thought (CoT), tree of thoughts (ToT), and ReAct can enable less capable models to perform comparably to much larger ones.
Another layer of sophistication is using control flow and forks to dynamically guide the model down the correct reasoning pathways and offload some processing tasks to external functions. These can also be used as mechanisms for preserving your context window token budget, by forking subtasks down branches outside of the main prompt flow, and then joining back in the summarised results of these forks.
Rather than overwhelm a small open source model with an overly complex task, deconstruct the problem into a logical flow of doable subtasks.
Constrained Decoding
🟢 Decreases costs
🟢 Improves task performance
For applications that involve generating structured outputs, such as a JSON objects, constrained decoding is a powerful technique that can:
- guarantee outputs that conform to the desired structure
- drastically improve throughput by accelerating token generation, and reducing the number of tokens that need to be generated
- improve task performance by guiding the model
I've written a separate article that explains the topic in detail:

OpenAI does offer a JSON mode, but this does not provide strong guarantees as to the structure of the JSON output — nor the throughput benefits — of strict constrained decoding.
Constrained decoding goes hand in hand with control flow strategies, as it enables you to reliably direct LLM applications down pre-specified pathways by constraining their responses to different branching options. It's very fast and inexpensive to have a model respond with short, constrained answers to long series of multi-turn conversation questions (remember: the speed of throughput is determined by the numbers of tokens that are generated).
There aren't any notable downsides to constrained decoding, so if your task requires structured outputs, you should be using it.
Caching, Model Quantisation, and Other Backend Optimisations
🟢 Decreases costs
⚪ Does not affect task performance
Caching is a technique used to speed up data retrieval operations by storing computed input:output pairs, and reusing the results if the same input is encountered again.
In non-LLM systems, caching is typically applied to requests that exactly match a previously seen request. Some LLM systems may also benefit from this rigid form of caching, but usually when building with LLMs, we don't expect to encounter the exact same inputs routinely.
Fortunately, there are sophisticated key-value caching techniques specifically for LLMs that are much more flexible. These can greatly accelerate text generation for requests that are partial but non-exact matches to previously seen inputs. This improves system throughput by reducing the volume of tokens that need to be generated (or at least accelerates them, depending on the specific caching technique and the scenario).
With proprietary LLMs, you don't have control over how caching is or isn't being performed for your requests. But for open source LLMs, there are various backend frameworks for LLM serving that can dramatically improve inference throughput, that can be configured to your system's bespoke requirements.
Beyond caching, there are other LLM optimisations that can also be used to improve inference throughput, such as model quantisation. By reducing the precision used for the model weights, it's possible to shrink the model size (and therefore its memory requirements) without significantly compromising the quality of its outputs. Popular models will typically have a plethora of quantised variants available on Hugging Face, contributed by the open source community, which saves you from having to perform the quantisation process yourself.
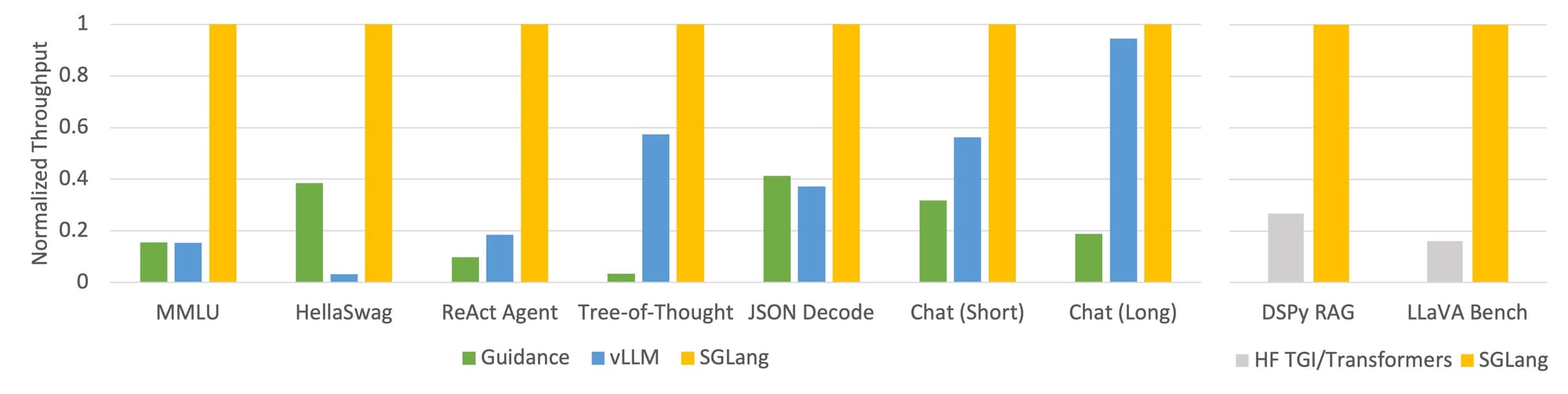
vLLM is perhaps the most established serving framework, boasting various caching mechanisms, parallelisations, kernel optimisations, and model quantisation methods. SGLang is a more recent player with similar capabilities as vLLM, and an innovative RadixAttention caching approach that claims especially impressive performance.
If you're self-hosting models, it's well worth using these frameworks and optimisation techniques, as you can reasonably expect to improve your throughput by at least an order of magnitude.
Model Fine-Tuning and Knowledge Distillation
⚪ Does not affect inference costs
⚪ Does not affect throughput
Fine-tuning encompasses various techniques that are used to adapt an existing model to perform better on a specific task. I recommend checking out Sebastian Raschka's blogpost on fine-tuning methods as a primer on the topic. Knowledge distillation is a related concept, where a smaller "student" model is trained to emulate the outputs of a larger "teacher" model on a task of interest.
Some proprietary LLM providers, including OpenAI, offer minimal fine-tuning capabilities. But only open source models provide full control over the fine-tuning process, and access to the full gamut of fine-tuning techniques.
Fine-tuning models can significantly improve task performance, without impacting inference costs or throughput. But fine-tuning does require time, skills, and good data to implement, and there are costs involved for the training process. Parameter-efficient fine-tuning (PEFT) techniques, such as LoRA, are particularly attractive as they provide the highest performance returns relative to the amounts of resources they require.
Fine-tuning and knowledge distillation are amongst the most powerful techniques for maximising model performance. They have no downsides when implemented correctly apart from the initial upfront investment required to perform them. However, you should be careful to ensure that fine-tuning has been conducted in a way that is consistent with other aspects of your system, such as the prompt flow and constrained decoding output structure. If there are discrepancies between these techniques, it may result in unexpected behaviour.
Optimal Model Sizing
🟢 Increase throughput
🟢 Decrease costs
🔴 Worsen task performance
This could equally have been framed as "Larger Models" with the pros and cons inverted. The key point is:
Most proprietary LLM providers offer a couple tiers of model size/capability. When it comes to open source, there's a dizzying array of model options at all sizes you could wish for up to 100B+ parameters.
As discussed in the multi-turn conversation section, we can simplify a complex task by breaking it down into a series of more manageable subtasks. But there will be a point at which the problem cannot be decomposed any further, or doing so would compromise aspects of the task that need to be tackled more holistically. This depends strongly on the use case, but there will be a sweet spot of task granularity and complexity that determines the right size of the model, as indicated by achieving adequate task performance at minimal model size.
For some tasks, this will mean using the biggest and most capable model you can; for other tasks, you may be able to use very small models (even non-LLMs).
In any case, elect to use the best-in-class model at any given parameter size. This can be identified by referring to public benchmarks and leaderboards, and changes regularly given the rapid pace of the field. Some benchmarks will be more relevant for your use case than others, so it's worth figuring out which are most applicable.
But don't assume that you can simply swap in the new best model and realise immediate performance gains. Different models have different failure modes and characteristics, so a system optimised around one model won't necessarily work well for another model — even if it is supposed to be better.
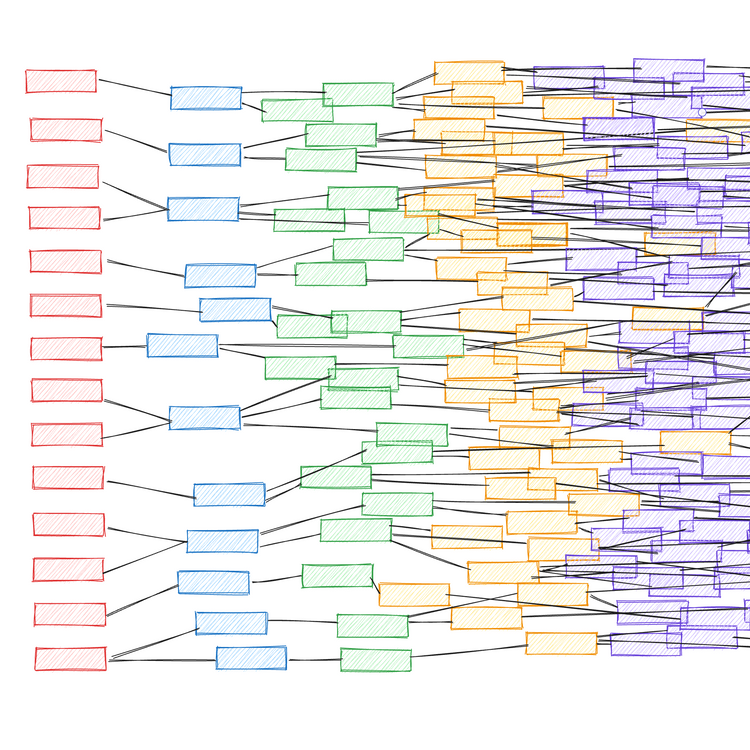
A Technical Roadmap
As previously mentioned, all of these strategies are complementary, and when combined, they compound to produce robust, well-rounded systems. But there are also dependencies between these techniques, and it's important to ensure they are aligned to prevent dysfunction.
The diagram below is a dependency map demonstrating a logical order in which to implement these techniques. This assumes the use case requires a structured output to be produced.
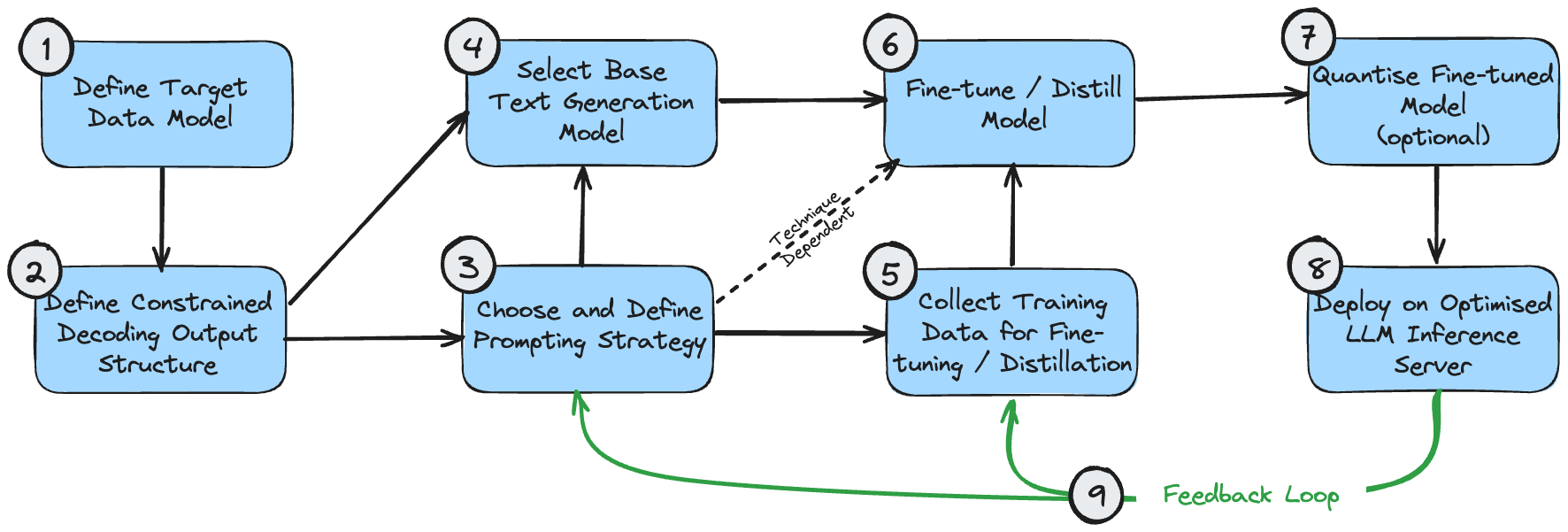
The stages can be understood as follows:
- The target data model is the ultimate output that you want to create. This is informed by your use case and the broader requirements of the overall system, beyond the generative text processing.
- The constrained decoding output structure could be identical to your target data model, or it may be slightly modified for optimal performance during constrained decoding. Refer to my constrained decoding article to understand why this might be the case. If it is different, you will need a post-processing stage to convert it to the final target data model.
- You should make an initial best guess as to what the right prompting strategy is for your use case. If the problem is straightforward, or cannot be decomposed intuitively, elect for a monolithic prompt strategy. If the problem is highly complex, with many granular subcomponents, opt for a mutli-prompting strategy.
- Your initial model selection is mostly a matter of optimal sizing, and ensuring the model characteristics meet the functional requirements of the problem. Optimal model sizing is discussed above. Model characteristics, such as the required context window length, can be calculated based on the expected output structure ((1) and (2)) and the prompt strategy (3).
- Training data for model fine-tuning must be aligned with the output structure (2). If using a multi-prompting strategy that incrementally builds the output, the training data must also reflect each stage of this process.
- Model fine-tuning/distillation naturally depends on your model selection, training data curation, and prompt flow.
- Quantisation of the fine-tuned model is optional. Your quantisation options will depend on your choice of base model.
- The LLM inference server will only support certain model architectures and quantisation methods, so ensure your previous selections are compatible with your desired backend configuration.
- Once you have an end-to-end system in place, you can establish a feedback loop for continuous improvement. You should be regularly tweaking the prompts and few-shot examples (if you're using these) to address examples where the system has failed to produce an acceptable output. Once you've accumulated a reasonable sample of failure cases, you should also consider performing further model fine-tuning using these examples.
In reality, the development process is never perfectly linear, and depending on the use case, you may need to prioritise optimising some of these components over others. But this is a reasonable foundation for designing a roadmap tailored to your specific requirements.
Conclusion
Open source models can be faster, cheaper, and better than proprietary LLMs. The way to achieve this is by engineering more sophisticated systems that play to open source models' unique advantages, and make the appropriate tradeoffs between throughput, cost, and task performance.
This design choice trades system complexity for overall performance. A valid alternative is to have a simpler, equally capable system powered by proprietary LLMs, but at higher cost and reduced throughput. The correct decision depends on your application, your budget, and your availability of engineering resources.
But don't be too quick to write off open source models without adapting your technical strategy to suit them — you might be surprised by what they can do.


Member discussion