The Convergence of Proprietary and Open Source LLMs
Open and private models are becoming more similar than they are different
How to Beat Proprietary LLMs With Smaller Open Source Models
Building your AI applications around open source models can make them better, cheaper, and faster
A Guide to Structured Generation Using Constrained Decoding
The how, why, power, and pitfalls of constraining generative language model outputs
Modern Data Engineering and the Lost Art of Data Modelling
Necessity was the mother of invention. Now, an abundance of cheap storage and compute makes for data anarchy.
Approximating Shapley Values for Machine Learning
The how and why of Shapley value approximation, explained in code
Gnillehcs' Model of Integration
What happens to segregated communities as people increasingly seek diversity?
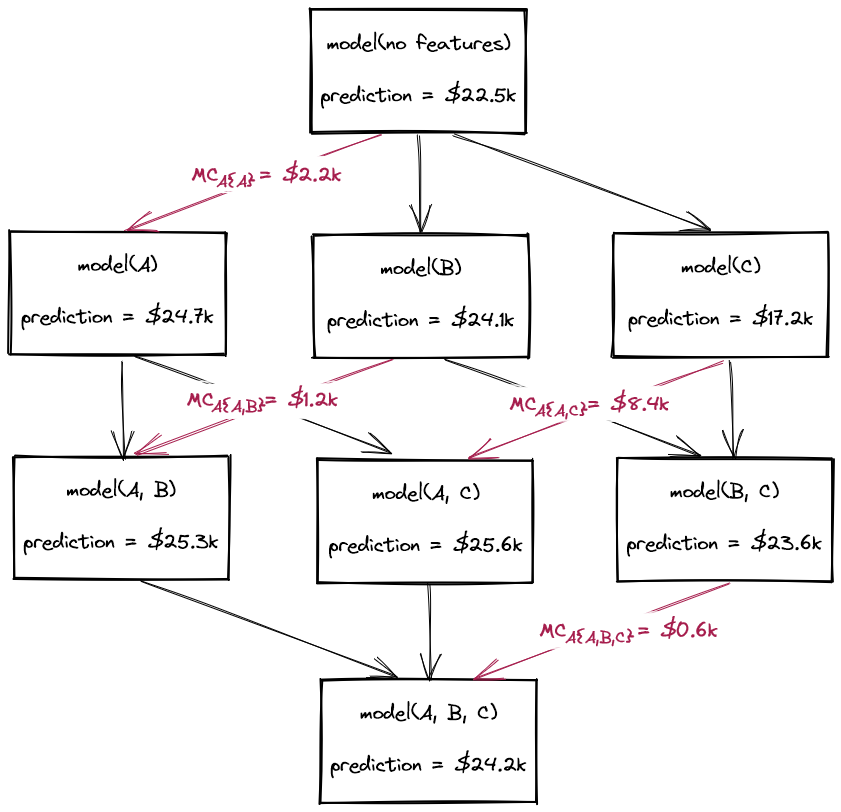
How Shapley Values Work
In this article, we will explore how Shapley values work - not using cryptic formulae, but by way of code and simplified explanations
Industry Perspective: Tree-Based Models vs Deep Learning for Tabular Data
Tree-based models aren't just highly performant - they offer a host of other advantages
4 Pandas Anti-Patterns to Avoid and How to Fix Them
pandas is a powerful data analysis library with a rich API that offers multiple ways to perform any given data
Supervised Clustering: How to Use SHAP Values for Better Cluster Analysis
Cluster analysis is a popular method for identifying subgroups within a population, but the results are often challenging to interpret