The Convergence of Proprietary and Open Source LLMs

A few months ago, I wrote about building LLM systems with self-hosted, open source models that beat proprietary services like GPT-4 and Gemini. The thrust of the piece is that although proprietary LLMs offer state of the art performance, they are expensive, and there are effective strategies that are only viable for local models.

However, the advantages enjoyed by open source models are diminishing: frontier commercial models are getting cheaper and their feature sets are expanding. Conversely, the state of the art performance boasted by proprietary LLMs is now being equalled by open source alternatives. This article explores this convergence.
Model Size, Speed, and Performance
The recent trend in frontier models from leaders like OpenAI and Google has been towards faster models that offer similar performance to the previous flagships. Whilst parameter counts aren't shared openly, based on the token generation speed, it's speculated that models like GPT-4o (mini) are in the ~10-200B parameter range. This is 1-2 orders of magnitude smaller than its predecessor, GPT-4, which is widely reported as having ~1.75T parameters. As the models get smaller, the API rate limits imposed on them become more generous, which is a boon for builders of scaled applications.
Meanwhile, the open source world has moved in the opposite direction. Meta's Llama 3.1 405B is the poster child for increasingly bigger and better open source models. NVIDIA's Nemotron-4 340B is another example of a company with vast GPU resources contributing a truly large open source language model to the community.
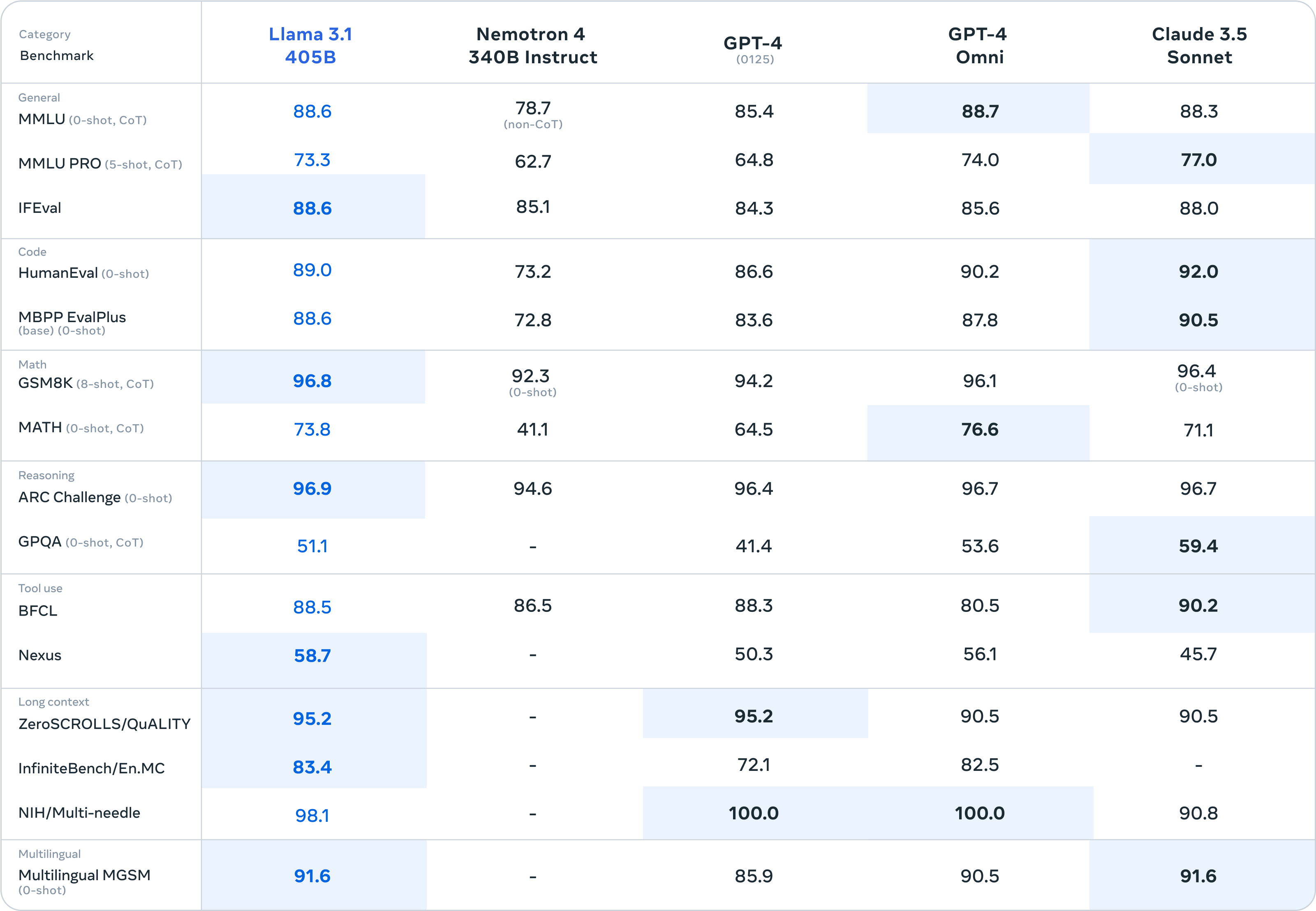
In the past, proprietary LLMs always had an edge over open source models on performance benchmarks at the frontier of the field. Now, leading models on each side look pretty similar with respect to both size and capability.
Feature Set and Model Characteristics
I've previously written about techniques that can be used with open source models that usually aren't viable with proprietary LLMs. However, this gap in capabilities is starting to narrow.
Constrained Decoding
Last week, OpenAI added constrained decoding support with their new Structured Outputs capability. This provides strong guarantees about the LLM response object and is a significant upgrade over prior "JSON modes" for applicable use cases. Similar features have also recently been released by Google and Cohere. These implementations of constrained decoding are not as flexible as what can be achieved when running models locally, but it's notable that commercial services are beginning to expose more advanced LLM programming techniques.

See my previous article for an introduction to constrained decoding
Advanced Caching Methods
Google didn't make much noise when announcing context caching for Gemini. But it has profound implications for the most popular LLM prompting techniques, reducing the input token costs of long, unchanging prompt prefixes by 75%. Coupled with Gemini's 1M+ token context window, context caching makes tried and tested strategies like extensive many shot prompting more cost viable.
Extensive Multi-Turn Conversations
Context caching may also unlock multi-turn conversation strategies for certain use cases. For proprietary LLM APIs, with each additional conversation turn, you repay all the prior conversation turns' tokens as additional input token costs. This means that your input token costs rapidly accumulate with every conversation turn, assuming you retain the full conversation as context. Context caching partially mitigates this, by discounting the costs incurred for the initial portion of the conversation, which often dwarfs the tokens in the rest of the exchange.
The more generous API rate limits that accompany smaller proprietary LLMs also eliminate a potential blocker to the adoption fo multi-turn conversation strategies.
Context Window Length
For a long time now, proprietary LLMs have boasted 100k+ token context windows, and in the case of Google's Gemini, 2M+. This had been a major pain point for open source models, with 8k context being the standard for most mainstream releases. Thankfully, Llama 3.1 brought open source models in line with their proprietary counterparts by natively supporting 128k context tokens.
Multimodality
Since the GPT-4 era, proprietary LLMs have emphasised their multimodal prowess. Much like long context windows, open source models have generally lagged behind on this front, but Meta looks set to release multimodal capabilities in its next Llama 3 iterations.
Inference Costs
Proprietary LLMs are getting cheaper. There's always been a price war going on between major providers as they fight to capture market share, and this continues to intensify.
Today (August 12th), Google are slashing the price of Gemini 1.5 Flash by 75%. This is entirely independent of the potential 75% saving on input token costs using context caching, as discussed above.
Other cost saving strategies such as batch inference — supported by both Google and OpenAI — offer 50% savings over the standard rates for time-insensitive inference use cases.
I'm reluctant to share price calculations comparing inference costs for proprietary LLM APIs versus self-hosted open source models, because they depend on a multitude of ever-changing factors and they will immediately become outdated. But anecdotally, the previous generations of leading proprietary models were often prohibitively expensive for inference at scale, but the new wave of smaller-cheaper-faster proprietary models are extremely competitive.
The big commercial players are offering their services at below cost and they benefit from economies of scale. What's more, it's no secret that the major providers sometimes offer further discounts on the public pricing to companies to win their business. Even if you ignore the labour overheads of maintaining your own infrastructure, unless you're using much smaller and weaker open source models, or somehow have access to underpriced GPUs, you'll likely find yourself paying more to self-host.
So Which Option Is Best for Me?
In summary, proprietary and open source LLMs are converging towards similar model sizes, speeds, capabilities, characteristics, and feature sets.
It's hard to overstate Meta's contributions towards levelling the playing field between open and private models. Meta are deploying the skills and resources typically only possessed by well-capitalised proprietary LLM companies, all to the benefit of the open source community. The result is, whether you're self-hosting a state of the art LLM or paying a commercial provider, under the hood, the models are fundamentally similar with respect to architecture and the way they were trained.
Who knows what secret sauce the leading commercial providers are withholding. Rumours abound about OpenAI's Q* project and its alleged AGI capabilities. It could be that we're temporarily experiencing a convergence in public and private model capabilities before the frontier is pushed out yet again by a release worthy of the GPT-5 moniker.
There will always be use cases for self-hosted, open source models. Privacy may be a concern. Proprietary LLMs may refuse to assist with controversial tasks. Some products require fast time-to-first-token generation, which may necessitate on-device models. Tinkerers experimenting with LLMs on their own hardware will always have a preference for self-hosting, unless proprietary services really do reach the point of "intelligence too cheap to meter".
The current wave of affordable proprietary LLMs are particularly compelling to anyone who doesn't want to maintain their own infrastructure and manage the complexities of efficient model serving. This will be true of most non-tech companies, who want to incorporate generative AI into their business, but lack the engineering expertise to deploy their own models.
Tech-savvy companies with bespoke requirements and a willingness to make committed investments into in-house solutions may still reap superior results from systems built around open models. But unlike at the beginning of 2024, it's now much harder to self-host with a better opex profile than using a proprietary service.
There's no clear winner yet in the great proprietary versus open source LLM debate. Both are still riding the unrelenting wave of AI progress, and neither looks to be slowing down any time soon.
Member discussion